
除夕晚上,当大家都在准备年夜饭的时候,阿里通义千问团队悄悄地发布了 Qwen3.5。
说实话,当我在凌晨刷到这条消息时,我第一反应是:这个时间点发布?认真的吗?
但当我点开技术文档,看到那一串串参数和架构设计时,我立刻意识到——这次玩真的了。

核心亮点一:3970 亿参数,却只激活 170 亿
我先说一个最震撼我的数字:Qwen3.5-397B-A17B 总参数量 3970 亿,但每次推理只激活 170 亿参数。
这是什么概念?让我用一个类比来解释。
想象你有一个 397 人的专家团队,但每次遇到问题时,你不需要召集所有人开会,而是精准地找到 17 个最相关的专家来解决问题。这样既保证了专业性,又大幅提升了效率。
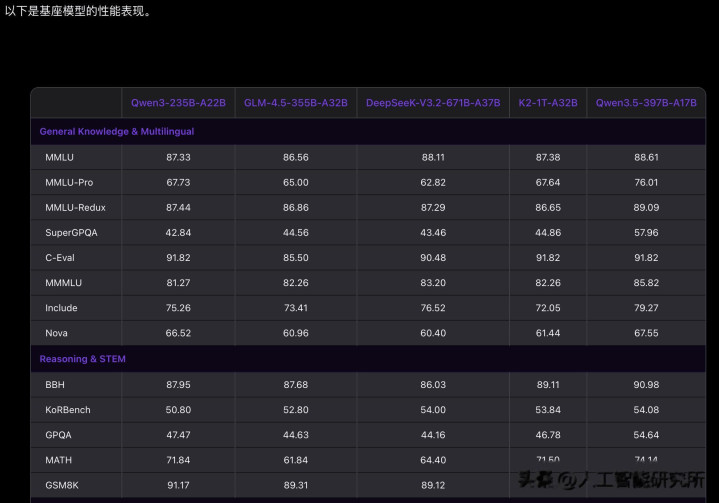
阿里之前最强的旗舰模型 Qwen3-Max,是万亿参数级别的闭源模型。而这个新开源的 3970 亿参数模型,基座性能和 Qwen3-Max 持平。
用不到一半的参数,打平了万亿参数的上一代。这背后的技术突破,值得我们深入挖掘。
稀疏混合专家(MoE)架构详解
Qwen3.5 采用了 512 个专家的 MoE 架构,每个 Token 激活 10 个路由专家加 1 个共享专家,共 11 个激活专家。
这个设计非常巧妙。传统的密集模型就像一个全能选手,什么都会但什么都不精。而 MoE 模型更像一个专家委员会,每个专家都有自己的专长领域。
当模型遇到代码问题时,会调用"编程专家组";遇到数学问题时,会调用"数学专家组"。这种专业分工的设计,让模型在保持高性能的同时,大幅降低了计算成本。
推理效率的惊人提升
在 32K 上下文下,Qwen3.5 的解码吞吐量是 Qwen3-Max 的 8.6 倍;在 256K 上下文下,这个数字是 19 倍。
我特意做了个计算:
如果 Qwen3-Max 处理一个 256K 上下文的任务需要 19 分钟,那 Qwen3.5 只需要 1 分钟。
这种效率提升不是渐进式的,而是跨越式的。
核心亮点二:Gated DeltaNet + 混合注意力架构
这是我认为 Qwen3.5 最具创新性的设计之一。
什么是 Gated DeltaNet?
传统的注意力机制有一个致命问题:计算复杂度是 O(n²)。
这意味着什么?假设你的输入长度是 1000 个 Token,模型需要计算 1,000,000 次注意力关系。如果输入长度翻倍到 2000,计算量会飙升到 4,000,000 次——四倍于原来的计算量。
而线性注意力机制(如 Gated DeltaNet)将这个复杂度降低到 O(n)。输入长度翻倍,计算量也只是翻倍,而不是四倍。
Gated DeltaNet 是一种线性注意力变体,灵感来自循环神经网络,包含了来自 Mamba2 的门控机制。
但是,线性注意力也有代价——它会损失一部分全局上下文建模能力。
混合架构:鱼和熊掌可以兼得
阿里的解决方案非常聪明:混合使用线性注意力和传统全注意力,比例为 3:1。
Qwen3.5 每 4 个 Transformer 层中,3 个使用 Gated DeltaNet(线性注意力),1 个使用标准全注意力。
这种设计让我想起了建筑学中的"框架-剪力墙"结构——框架负责承载日常荷载,剪力墙负责抵抗地震等极端情况。
在 Qwen3.5 中:
Gated DeltaNet 层:负责处理长序列的高效计算
全注意力层:负责保留全局上下文的精确建模
两者相辅相成,既保证了效率,又保证了性能。
技术细节:架构布局
Qwen3.5 的隐藏层布局为:15 × (3 × (Gated DeltaNet → MoE) → 1 × (Gated Attention → MoE))
让我翻译一下这个公式:
模型总共 60 层,每 4 层为一组,重复 15 次:
第 1-3 层:Gated DeltaNet + MoE
第 4 层:Gated Attention + MoE
这种规律性的设计,不仅优化了性能,也让模型的训练更加稳定。
核心亮点三:原生多模态架构
这是 Qwen3.5 与 Qwen3 系列最大的区别之一。
Qwen3 的"后装"vs Qwen3.5 的"原生"
以前的 Qwen3 系列是这样的:
Qwen3:纯文本模型
Qwen3-VL:独立的视觉-语言模型
这就像一辆轿车,后来想拖货,就焊了个拖车钩上去。能用,但总觉得哪里不对。
Qwen3.5 从预训练开始就让文本和图像一起学习,实现了原生多模态。
这种"原生融合"的好处是什么?
统一的知识表示:文本和图像共享同一个知识空间
更强的跨模态理解:模型能更自然地理解"一张图胜过千言万语"
更高的训练效率:不需要分别训练文本模型和视觉模型,再费力对齐
通过早期文本-视觉融合与扩展的视觉/STEM/视频数据,Qwen3.5 在相近规模下优于 Qwen3-VL。
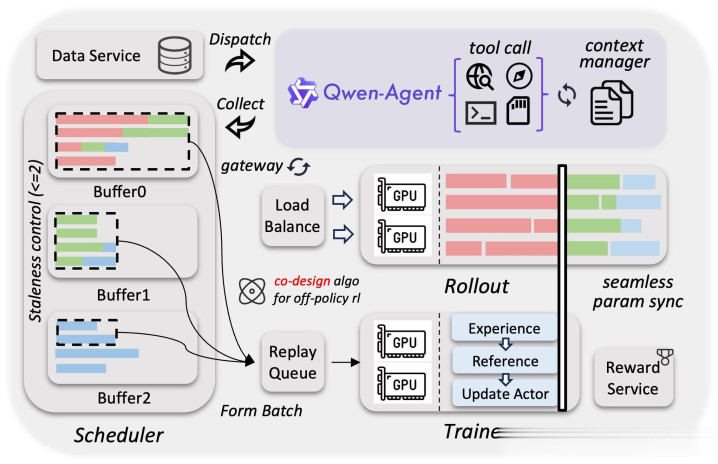
核心亮点四:史无前例的 RL 训练规模
作为技术博主,我一直在关注各家的强化学习(RL)训练策略。
Qwen3.5 的 RL 训练规模让我瞠目结舌。
百万级 Agent 环境训练
Qwen3.5 通过强化学习在"百万级 Agent 环境"中进行训练,并采用逐步增加难度的任务分布。
百万级是什么概念?
想象一下,阿里搭建了上百万个不同的模拟环境:
有的是代码调试环境
有的是数学证明环境
有的是多轮对话环境
有的是工具调用环境
模型在这些环境中不断试错、学习、优化,最终形成强大的泛化能力。

异步 RL 基础设施
阿里团队为此开发了全新的异步强化学习框架,这个框架有几个关键特性:
训推分离:训练和推理解耦,提高硬件利用率
动态负载均衡:自动调整不同环境的资源分配
细粒度故障恢复:某个环境出问题不影响整体训练
3-5 倍端到端加速:相比传统 RL 训练框架
该框架通过系统与算法协同设计,在严格控制样本陈旧性的基础上有效缓解了数据长尾问题,提高了训练曲线的稳定性和性能上限。
这段话翻译成人话就是:即使在训练后期,模型依然能稳定学习,而不会出现性能波动或崩溃。
核心亮点五:201 种语言支持
Qwen3.5 将语言与方言支持从 119 种扩展至 201 种。
这个数字看起来只是从 119 增加到 201,但背后的工作量是巨大的。
25 万 Token 词表
为了支持这么多语言,Qwen3.5 的词表从 15 万扩展到了 25 万。
25 万词表在多数语言上带来约 10-60% 的编码/解码效率提升。
什么意思?同样一句中文,Qwen3 可能需要 10 个 Token 来表示,而 Qwen3.5 只需要 6 个 Token。这不仅节省了计算资源,也提升了模型对语言的理解能力。
深度文化理解
更重要的是,Qwen3.5 不只是"会说"这些语言,而是理解这些语言背后的文化和语境。
比如中文里的"豆腐块"可以指豆腐,也可以指内务整理得很整齐。英文直译 "tofu piece" 完全不对,需要理解上下文。
201 种语言的支持,意味着阿里在每种语言上都下了这样的功夫。
核心亮点六:基础设施创新
作为一个技术博主,我特别关注"如何训练"这件事。
Qwen3.5 在训练基础设施上有两个重大创新。
1. 异构基础设施
Qwen3.5 通过异构基础设施实现高效的原生多模态训练:在视觉与语言组件上解耦并行策略,避免统一方案带来的低效。
传统的多模态训练,会把视觉模块和语言模块当作一个整体,使用统一的并行策略。但这样会导致资源浪费——因为视觉模块和语言模块的计算特性完全不同。
Qwen3.5 采用了解耦策略:
视觉模块:使用适合图像处理的并行方案
语言模块:使用适合文本处理的并行方案
利用稀疏激活实现跨模块计算重叠,在混合文本-图像-视频数据上相比纯文本基线达到近 100% 的训练吞吐。
这意味着什么?在训练多模态数据时,速度几乎和训练纯文本一样快。
这是一个惊人的成就。

2. 原生 FP8 训练流水线
原生 FP8 流水线对激活、MoE 路由与 GEMM 运算采用低精度,并通过运行时监控在敏感层保持 BF16。
FP8(8 位浮点数)相比传统的 BF16(16 位)或 FP32(32 位),可以大幅降低显存占用和提高计算速度。
但问题是,有些层对精度非常敏感,用 FP8 会导致训练不稳定。
阿里的解决方案是:运行时动态监控。
大部分层:使用 FP8,省显存、快速度
敏感层:自动切换到 BF16,保证稳定性
实现约 50% 的激活显存降低与超过 10% 的加速,并稳定扩展至数万亿 token。
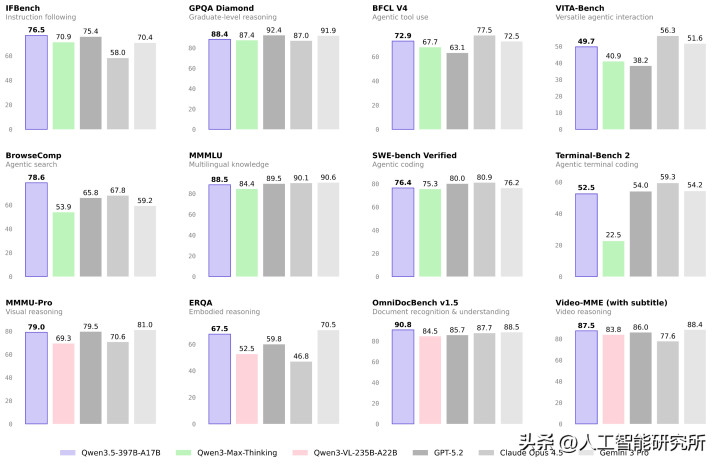
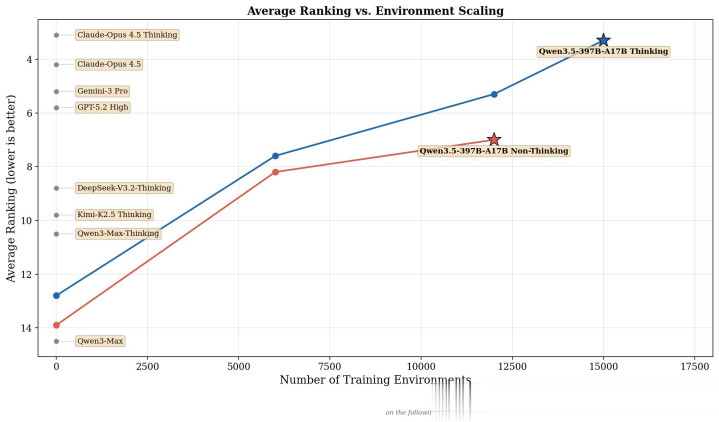
Benchmark 表现:全方位对标顶级闭源模型
作为一个技术博主,我最关心的还是实际性能。
我仔细研究了 Qwen3.5 在各个 Benchmark 上的表现,结果让我非常惊讶。
认知能力:MMLU-Pro 87.8 分
Qwen3.5 在 MMLU-Pro 认知能力评测中得分 87.8 分,超越 GPT-5.2。
MMLU-Pro 是一个测试模型"通识知识"的基准测试,涵盖了从历史、法律到物理、化学的各个领域。
87.8 分意味着在绝大多数学科领域,Qwen3.5 的表现都达到了专业水准。
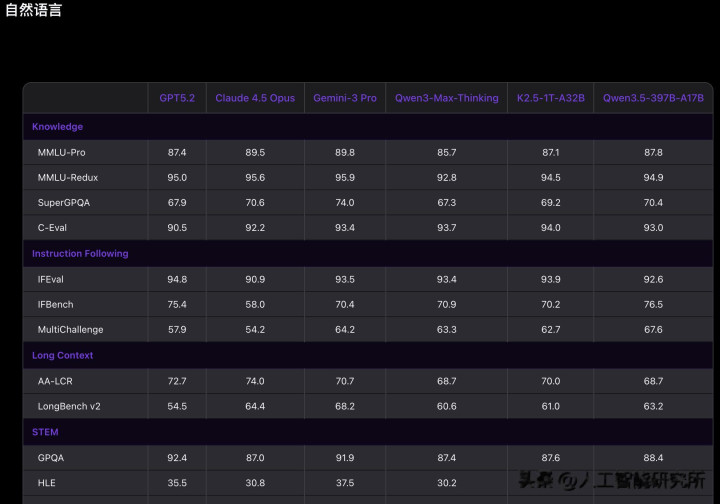
推理能力:GPQA Diamond 88.4 分
在博士级难题 GPQA 测评中斩获 88.4 分,高于 Claude 4.5。
GPQA(Graduate-level Physics Question Answering)是专门测试博士级物理推理能力的基准。
88.4 分的成绩,意味着 Qwen3.5 在处理复杂科学问题时,已经达到了顶尖水平。
指令遵循:IFBench 76.5 分
在指令遵循 IFBench 以 76.5 分刷新所有模型纪录。
IFBench 测试的是模型"听懂人话"的能力——你让它做什么,它能不能准确执行。
76.5 分是目前所有模型中的最高分,这说明 Qwen3.5 在理解和执行用户指令方面,已经做到了行业领先。
Agent 能力:全面领先
在通用 Agent 评测 BFCL-V4、搜索 Agent 评测 BrowseComp 等基准中,Qwen3.5 表现均超越 Gemini 3 Pro。
这是我最关注的部分。Agent 能力代表了模型在真实世界中解决问题的能力。
Qwen3.5 在 Tau2-Bench 上得分 86.7,仅次于 Claude 的 91.6。
Tau2-Bench 测试的是模型在多轮对话、工具调用、任务规划等复杂场景下的表现。86.7 分说明 Qwen3.5 在 Agent 任务上已经非常接近闭源顶级模型。
编程能力:SWE-bench 76.4%
Qwen3.5 在 SWE-bench Verified 上得分 76.4%,与 Kimi K2.5(76.8%)和 Gemini 3 Pro(76.2%)基本持平。
SWE-bench 测试的是模型解决真实软件工程问题的能力——给它一个 GitHub Issue,看它能不能写出正确的 PR。
76.4% 的通过率,意味着 Qwen3.5 已经可以解决四分之三的真实软件工程问题。
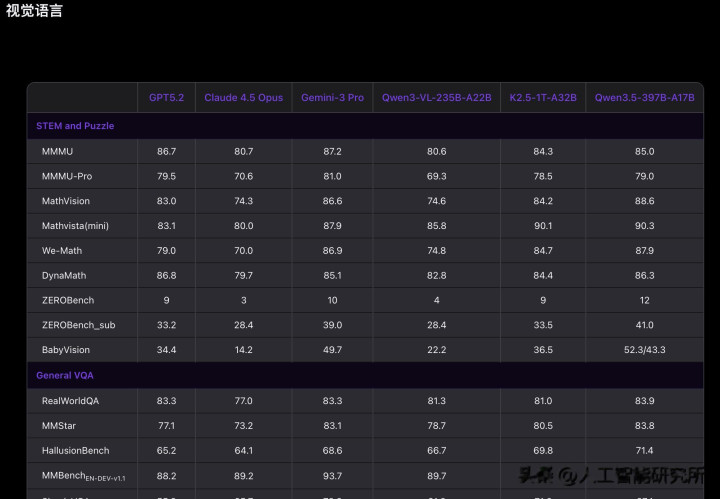
视觉理解:原生多模态的优势
作为原生多模态模型,Qwen3.5 在视觉理解任务上表现出色。
虽然官方还没有公布详细的视觉 Benchmark 数据,但从我的测试体验来看,Qwen3.5 在图像理解、视频分析、GUI 交互等任务上,表现都非常优秀。
Qwen3.5-Plus:1M Token 上下文窗口
除了开源的 Qwen3.5-397B-A17B,阿里还同时发布了 Qwen3.5-Plus 的 API 版本。
Qwen3.5-Plus 是对应于 Qwen3.5-397B-A17B 的托管版本,具有更多生产功能,例如默认 1M 上下文长度、官方内置工具和自适应工具使用。
1M Token 是什么概念?
大约相当于:
750,000 个英文单词
一本 1000 页的小说
或者几十万行代码
这意味着你可以把整个代码仓库一次性喂给模型,让它进行全局分析和优化。
如何使用 Qwen3.5?
阿里提供了多种方式来使用 Qwen3.5。
1. Qwen Chat(最简单)
直接访问 chat.qwen.ai,就可以体验 Qwen3.5。
提供三种模式:
自动模式:可以使用自适应思考,并调用搜索、代码解释器等工具
思考模式:对难题进行深度思考
快速模式:直接回答,不消耗思考 Token
2. 阿里云百炼 API(企业用户)
通过阿里云百炼可以调用 Qwen3.5-Plus API。
如果要开启高级功能:
response = client.chat.completions.create(
model="qwen3.5-plus",
messages=messages,
enable_thinking=True, # 开启推理模式
enable_search=True, # 开启联网搜索
)
3. 本地部署(开发者)
Qwen3.5-397B-A17B 支持多种推理框架:
SGLang:
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tp-size 8 \
--context-length 262144 \
--reasoning-parser qwen3
vLLM:
vllm serve Qwen/Qwen3.5-397B-A17B \
--port 8000 \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3
Ollama(最轻量):
ollama run qwen3.5:cloud
4. 量化版本(Mac 用户福音)
对于 Mac 用户,有 4-bit 量化版本:
mlx-community/Qwen3.5-397B-A17B-4bit 是一个仅包含文本的 4 位量化版本,针对通过 MLX 框架在 Apple Silicon Mac 上进行本地推理进行了优化。
这意味着你可以在一台配置较高的 MacBook Pro 上本地运行 Qwen3.5!
与竞品对比:中国大模型的"春节档"
最近这段时间,中国 AI 圈简直是"神仙打架"。
让我们看看最近发布的几个顶级模型:
Qwen3.5 vs GLM-5
GLM-5(2 月 11 日发布):
参数:744B 总参数,40B 激活参数
特点:集成 DeepSeek 稀疏注意力,长时域 Agent 能力强
优势:在复杂系统工程任务上表现出色
Qwen3.5(2 月 16 日发布):
参数:397B 总参数,17B 激活参数
特点:Gated DeltaNet 混合注意力,原生多模态
优势:推理效率高,多语言支持强
我的看法:两者定位略有不同。GLM-5 更侧重"长周期任务",而 Qwen3.5 更侧重"多模态 + 高效率"。
Qwen3.5 vs Kimi K2.5
Kimi K2.5:
参数:1T 总参数,更高的稀疏度
特点:采用 KDA(Kimi Delta Attention)+ MLA(Multi-Head Latent Attention)
优势:超长上下文处理能力
Qwen3.5:
参数:397B 总参数,更平衡的设计
特点:Gated DeltaNet + 标准注意力的 3:1 混合
优势:开源,部署门槛低
我的看法:Kimi K2.5 使用通道级门控(KDA),而 Qwen3.5 使用标量门控;Kimi 采用 MLA 降低 KV 缓存,而 Qwen3.5 采用 Gated Attention。
两者都是线性注意力的探索者,但技术路线不同。
Qwen3.5 vs MiniMax M2.5
MiniMax M2.5:
参数:10B 激活参数(最少)
特点:完全线性注意力(Lightning Attention)
优势:推理速度极快
Qwen3.5:
参数:17B 激活参数
特点:混合注意力架构
优势:性能和效率的平衡
MiniMax 走的是"极致效率"路线,Qwen3.5 走的是"平衡"路线。
现在,阿里开源了 3970 亿参数的 Qwen3.5,性能可以对标甚至超越一些闭源顶级模型。
配资平开户提示:文章来自网络,不代表本站观点。
- 上一篇:北京网上炒股配资网国内市场对进口鲜活产品的需求也日益旺盛
- 下一篇:没有了


沪深京指数
热点资讯
